This post will go into the details of the tool developed by LinkedIn known as Apache Kafka and how different companies like Netflix, LinkedIn, Uber, Instagram, Twitter, and Honeywell uses this tool.

After reading this post, you'll know the answers to the below question:
- What is Kafka?
- Who developed Kafka?
- Why we use Kafka? What problem does it solve?
- What are the various use cases of Kafka in REAL-WORLD?
- How different companies use it?
All of the concepts are explained like you're 5.
Kafka was initially developed by Linkedin to implement or solve the problem of a website activity tracker, sending logs to the server and to build custom data pipelines.
Quick note: website activity tracker tracks and collects all of the activities that took place on website(like user liking a post, searching for something, comment, spending X amount of time on Y post, clicking on a profile).
All of these events/activities are sent to servers.
Technical definitions:
- Kafka is a messaging system used to produce and consume messages from a topic.
- Kafka is a distributed streaming platform.
- Kafka is used to storing the messages(data)
I'll break them down further. But before that let's cover key components of Kafka.
Components of Kafka:
- ZooKeeper
- Topic
- Records
- Brokers
Think of Kafka as an interface, a way to connect different sources, like a pipeline. It is used to transfer the data from one place to another.
-
Records are nothing but messages(data) in Kafka terminology that is being transferred from one data source to another.
-
Topic is like a queue that categorically stores those messages. Example: one topic for messages related to products, one topic for logs, one topic for events.
-
Brokers: Kafka is deployed as a cluster(made up of different servers). These individual servers are known as brokers.
-
Zookeeper is used to manage a cluster. It keeps track of all topics, records, and all of the configuration-related information.
Kafka is based on Publisher-Subscriber model.
What does that mean?
Think of it as a newsletter. A publisher publishes newsletters(messages), subscribers subscribe to the newsletter(topic) and then they receive new posts(messages) whenever the publisher publishes a post.
This is the exact way how Kafka works.
Many sources publish the messages(data), and consumers consume them.
Enough theory, let's get into the application of Kafka.
Kafka as a Messaging System
Messaging system is like an interface that is used to build data pipelines.
Data pipeline: sending the messages(data) from one source to another. All of this comes under Data engineering.
Problem: When sending the messages from one source to multiple sources, what should be a robust, scalable, and efficient way to do so?
- We don't want data to be lost.
- We don't want to build multiple different interfaces between different sources.
Solution: This is where Kafka comes into the play. Producers publish the message to a topic. Many destination consumers subscribe to the topic and then keep receiving messages.
Kafka decouples event/message/data producers from data consumers.
Kafka as a Storage System
Because of durability and it's fault-tolerance nature, Kafka is used to store the stream of records or messages.
Kafka as a stream processing platform
Streaming data: data that's coming continuously from various sources and that needs to be processed either in real-time or after some time.
Used by both OLAP based systems or OLTP based systems.
Ex: log data, event data, lots of events that are happening on any e-com website like click on the product, add to cart, buy, similar items.
Kafka is used to moving, collect streaming data from one place to another.
Now, let's explore how different tech giants use Kafka.
- LinkedIn use Kafka heavily to build many custom data pipelines and to track activity data on the website. Remember activity data from top tweets in this post?
Each activity has it's own topic and those activities are then sent to topics as per its nature.
That collected data is then used for data processing and analysis.
- Netflix use Kafka as a storage system in its Keystone pipeline.
Keystone is Netflix's data backbone that focuses on data analysis. Kafka at Netflix is responsible for producing, collecting, processing, aggregating, and moving all microservice events in near real-time and it also stores them on a temporary basis.
- Uber use Kafka for both real-time and batch processing tasks
Real-time processing tasks like computing business metrics, processing logs data, sending alerts to developers whenever something goes wrong.
Batch-processing tasks like sending data from one source to another. Doing ETL(extract-load-transform) tasks.

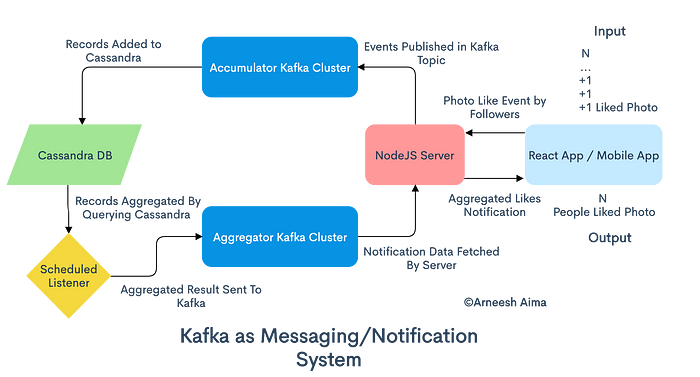
- Instagram and Twitter use Kafka as a notification/messaging system
Activities like the number of likes, comments, number of shares are sent to databases like Cassandra using Kafka as an interface.
Aggregation queries are executed on the top of those DBS.
Results(total number of likes) are then returned and published back to another Kafka topic.
References:
- https://insidebigdata.com/2016/04/28/a-brief-history-of-kafka-linkedins-messaging-platform/
- https://kafka.apache.org/
- https://medium.com/swlh/apache-kafka-startup-guide-system-design-architectures-notification-system-web-activity-tracker-6dcaf0cf8a7
- https://www.slideshare.net/AmazonWebServices/bdt318-how-netflix-handles-up-to-8-million-events-per-second
- https://eng.uber.com/ureplicator-apache-kafka-replicator/
- https://research.fb.com/wp-content/uploads/2016/11/realtime_data_processing_at_facebook.pdf