Machine learning plays a significant role in how things work at twitter.
There are mainly five use cases of machine learning at twitter:
- Personalized search: whenever a user searches for anything on twitter, the results are shown as per his profile, what he likes, whom he follows, what kind of tweets he posts, and things like that.
- Recommendation: whenever you visit the profile of someone or follow someone, twitter recommends similar profiles to follow along with those interests.
- Hiding sensitive content: Twitter detects and hides the sensitive media(porn, drugs, etc) on the timeline.
- Ads: which ad should be shown to which user so that he clicks or do whatever the call to action is. Showing relevant ads to users.
- Twitter timeline: Only show those tweets in which the user is highly interested in.
We're going to focus on the last use case: Twitter timeline. How does this work? How does the architecture look like?
Mapping the business problem to the machine learning problem.
Business problem: Only show those tweets in which the user is highly interested in.
Machine learning problem: Given a user and a tweet, predict the user's probability of engaging with it.
What's engagement? Like, comment, retweet, all these metrics come under engagement.
Architecture of twitter timeline
Twitter uses micro-service architecture to solve the problem.
Pipeline:
- Requesting tweets: First, the client requests for tweets. This happens whenever a user logs into his Twitter account.
- The request is sent to the tweet service.
- Tweet service forwards the request to the candidate service. The role of candidate service is to fetch all of the possible tweets at any particular time for that user.
- Then, all of the candidate tweets are returned to tweet service as the response.
- All of those candidate tweets are then send to prediction service by tweet service. The role of the prediction service is to score the tweets based on engagement. This is where machine learning comes into the picture.
- Candidate tweets with scores are then sent to tweet service.
- Tweet service then sorts those tweets based on the score in decreasing order and then return those tweets to client/user.
- The tweets which are finally shown to user are stored as the training data for the re-training of the machine learning model in prediction service. And the real-time engagement that the user had with those tweets are stored as true_labels for the data.
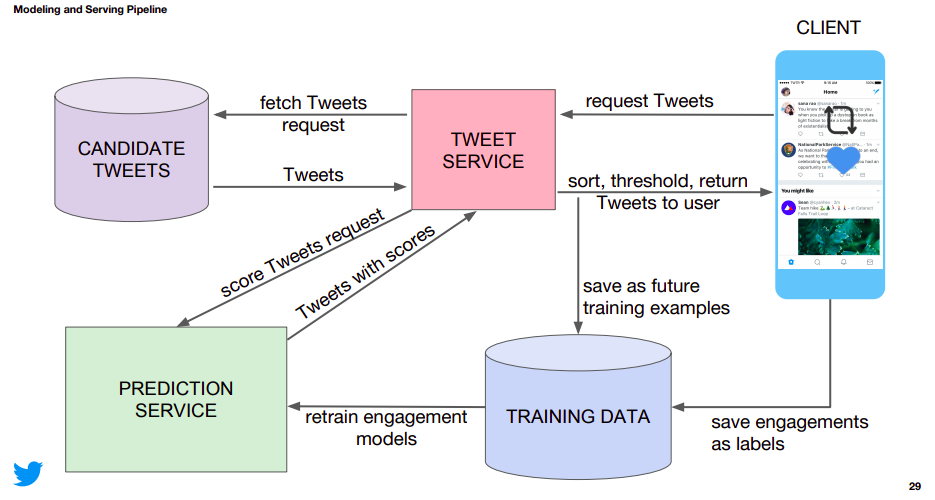
This is a very high-level overview of how twitter timeline architecture works.
Many questions need to be explored:
- How candidate tweets exactly works? How it fetches all of the tweets, especially the tweets that are liked by those users whom the client is following?
- How does a machine learning model/architecture of prediction service look like?
- What database does twitter use for collecting future training data?
- How engagement is collected and then send over to tweet service in real-time?
- How these services communicate with each other? Through APIs or something else?
- What this service so fast to run in production enviroment?
I'm on the journey to explore and learn about how twitter works technically. So, Will be posting my learning notes frequently on this blog.
References:
1.https://conferences.oreilly.com/artificial-intelligence/ai-ny-2019/public/schedule/detail/73559